Implementing a Trie in Ruby
In my last post I talked about benefits, reasons, and potential pitfalls of using tries. For a quick refresher, a trie, often called a prefix-tree is a a data type that is great to use for matching string patterns. Check out the wikipedia article for more info. For this post I will talk about how to implement a trie in Ruby.
The Groundwork
The first thing we want to do to build this trie is set up a Trie class that can initialize with a specialized nested hash. Since this will the actual data structure of the trie we can call it tree
1 2 3 4 5 6 7 8 9 | |
When we call Trie.new the above code will initialze a new instance of Trie with an instance variable tree. We build our nested hash specifically so that when we try to access a key in it, if the key is present we will get the value of that key, but if the key is not present then a new key-value pair will be added to the hash. When a new pair is added, the key will be the value we tried to access and the value will be an empty hash. This would normally only work on the first level of our hash, but since we want to build empty hashes this way no matter how deep our nesting goes we can call default_proc (which returns any block passed to Hash.new for a specific instance of Hash) as a proc on Hash.new in the block we first provided to Hash.new so that each new hash created on access is built with the same functionality.
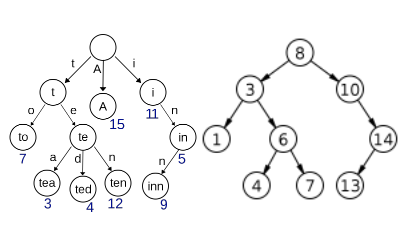
Now, when we add characters to our custom nested hash in a specific way we will get a trie structure with each key pointing to a value that is a hash of the next character in the string. Below is an example for the strings “cat” and “car”.
1 2 3 4 5 6 7 8 9 10 | |
Inserting Strings
Since we now have a nested hash functioning like we want the next step is to build a method that can add a string to our tree. I’ll call this method #insert and it must take a string like "cat" and access each section of the string independently (tree["c"]["a"]["t"]) just like above.
1 2 3 4 5 6 | |
The first thing we do after isolating the characters in the argument string is to set up a variable pointer. pointer is set to the current state of self.tree (starting with {}). Then in the next line we loop through all but the last character in our characters array. For each character we set our pointer to the return value of that key. If that character is in our tree in that position, the pointer will move to the the value of that key and if that character is not present at that level of the tree then an empty hash will be created as the value and pointer will be moved to that hash, in which the next character of the string will be nested.
After all but the last characters are added we add the last character followed by the key true. We will later use this true to check that we have reached the end of a word in our trie.
Finding Matches
Once we add all the words to trie we need check what words have been added so we can build a method called match which will take a string and return true or false depending on weather the word is in our trie.
1 2 3 4 5 6 7 | |
match works similarly insert but in reverse. First we split the argument into characters (like in insert), then we set a variable called pointer to the current state of our tree (also like in insert), and then we loop through all the characters setting pointer to the return value of calling fetch on pointer for each character. We also rescue nil for this line and the next so that we will not get errors in instances where characters are not found in tree.
We use fetch here in order to set a default return of nil when we try to fetch an invalid key instead of getting an error, or creating a new empty hash, which would have happened had we used the tree["c"] syntax with a non-present key. After the loop terminates pointer points to tree.fetch(characters.last, nil) so we call fetch(true, nil) on the last character to make sure that the word ends at that point in the trie. If it does we get {} and if not we get nil. We then compare our result to {} and return the proper true/false value.
Next Steps
After building a simple Trie in Ruby I want to end by listing a few next steps for this code.
- Partial match support - Partial match support would be a very useful tool for a trie. A method like
partial_match(substring)that could return all words in the trie containing the provided substring would be useful for finding similarity instead of indenticlal matches - Wildcard Support - A method that could take a string containing designated wildcard characters and return true or false for matches would be useful for finding pattern segments
- Initialize with strings - Creating a trie that could initialize with an array of strings would make adding strings and could be accomplished with an
add_multiple_strings(array)method that leveradges the*operator or just takes an array argument. - Javascript - Implementing a trie in Javascript would be very useful and could be used as a look up for custom predictive text in searches and many other features.